Note: For the best listening experience, we recommend setting your system volume to around 30%-35%.
Please be aware that the Source and Reference audio samples might be louder. Consider lowering the volume slider in the player controls for these samples to protect your hearing.
VoiceCloak: A Multi-Dimensional Defense Framework against Unauthorized Diffusion-based Voice Cloning
Abstract
Diffusion Models (DMs) have achieved remarkable success in realistic voice cloning (VC), while they also increase the risk of malicious misuse. Existing proactive defenses designed for traditional VC models aim to disrupt the forgery process, but they have been proven incompatible with DMs due to the intricate generative mechanisms of diffusion. To bridge this gap, we introduce VoiceCloak, a multi-dimensional proactive defense framework with the goal of obfuscating speaker identity and degrading perceptual quality in potential unauthorized VC. To achieve these goals, we conduct a focused analysis to identify specific vulnerabilities within DMs, allowing VoiceCloak to disrupt the cloning process by introducing adversarial perturbations into the reference audio. Specifically, to obfuscate speaker identity, VoiceCloak first targets speaker identity by distorting representation learning embeddings to maximize identity variation, which is guided by auditory perception principles. Additionally, VoiceCloak disrupts crucial conditional guidance processes, particularly attention context, thereby preventing the alignment of vocal characteristics that are essential for achieving convincing cloning. Then, to address the second objective, VoiceCloak introduces score magnitude amplification to actively steer the reverse trajectory away from the generation of high-quality speech. Noise-guided semantic corruption is further employed to disrupt structural speech semantics captured by DMs, degrading output quality. Extensive experiments highlight VoiceCloak's outstanding defense success rate against unauthorized diffusion-based voice cloning.
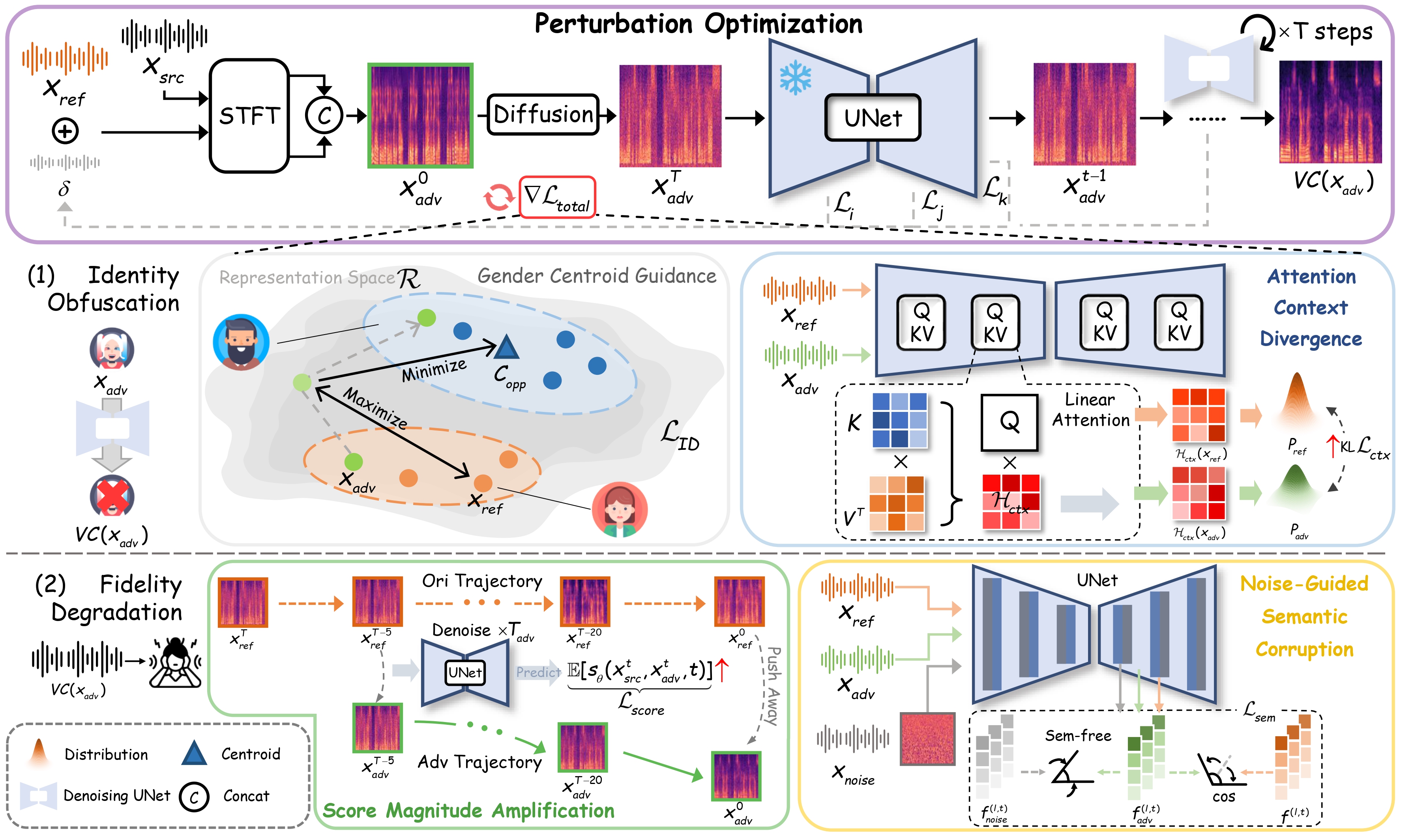
Figure 1: Overview of the proposed VoiceCloak framework.
Defense Effectiveness Comparison on Many-to-Many Voice Cloning
All speakers are unseen during the synthesis model's training phase. For fair comparison, all baseline methods are evaluated under same settings. We conducted same-gender voice conversions (e.g., male-to-male, female-to-female) as this typically yields more realistic generation results in standard VC.
Male-to-Male
id: 3000
Prompt: Only a little food will be required.
id: 174
Adversarial Ref.
Undefened
Random Noise
Attack-VC
VoicePrivacy
VoiceGuard
VoiceCloak
id: 3000
Prompt: Only a little food will be required.
id: 2902
Adversarial Ref.
Undefened
Random Noise
Attack-VC
VoicePrivacy
VoiceGuard
VoiceCloak
Female-to-Female
id: 6345
Prompt: I don't understand a single word you say!
id: 1988
Adversarial Ref.
Undefened
Random Noise
Attack-VC
VoicePrivacy
VoiceGuard
VoiceCloak
id: 6345
Prompt: I don't understand a single word you say!
id: 6319
Adversarial Ref.
Undefened
Random Noise
Attack-VC
VoicePrivacy
VoiceGuard
VoiceCloak
Ablation Studies
Detailed ablation studies are performed to isolate and verify the contribution of each proposed objective function $\mathcal{L}$ to the overall defense performance.
Identity Obfuscation
id: 6345
Prompt: I don't understand a single word you say!
Undefened (id: 1462)
VoiceCloak
$\mathcal{L}_{ID}$
$\mathcal{L}_{ID}$ w/o. Gender
$\mathcal{L}_{ctx}$
$\mathcal{L}_{ID} + \mathcal{L}_{ctx}$
id: 3000
Prompt: Only a little food will be required.
Undefened (id: 2428)
VoiceCloak
$\mathcal{L}_{ID}$
$\mathcal{L}_{ID}$ w/o. Gender
$\mathcal{L}_{ctx}$
$\mathcal{L}_{ID} + \mathcal{L}_{ctx}$
Perceptual Fidelity Degradation
id: 3000
Prompt: Only a little food will be required.
Undefened (id: 2086)
VoiceCloak
$\mathcal{L}_{score}$
$\mathcal{L}_{sem}$
$\mathcal{L}_{sem}$ w/o. Sem-free
$\mathcal{L}_{score} + \mathcal{L}_{sem}$
id: 6345
Prompt: I don't understand a single word you say!
Undefened (id: 6313)
VoiceCloak
$\mathcal{L}_{score}$
$\mathcal{L}_{sem}$
$\mathcal{L}_{sem}$ w/o. Sem-free
$\mathcal{L}_{score} + \mathcal{L}_{sem}$
Introducing Adversarial Perturbations with Different Budgets ($\epsilon$)
We investigated the impact of varying the perturbation budget to explore the trade-off between defense strength and perturbation imperceptibility. Based on below results, we selected a budget $\epsilon = 0.002 $ that offers a reasonable balance between robust defense performance and acceptable perturbation.
Prompt: The second part begins here, "I was a-thinking." The first part divides into two.
Prompt: The man's eyes looked as if they would burst out of his head.